
Restauration de Linux : pourquoi cela ne fonctionne-t-il pas souvent ?
De nos jours, la popularité du système d’exploitation Linux ne cesse de croître auprès d’un plus grand nombre d’utilisateurs. Son avantage évident est avant tout la distribution gratuite. De plus, ce système d’exploitation offre une énorme variété de versions et leurs dérivés qui couvrent les besoins variés des utilisateurs dans des appareils allant des téléphones mobiles aux superordinateurs.
Le système d’exploitation Linux utilise différents systèmes de fichiers qui comprennent Ext2, Ext3 et Ext4, XFS, ReiserFS, JFS (JFS2), etc. Les systèmes de fichiers Linux diffèrent en termes de fonctionnalités, chacun servant à certaines fins. Dans le processus de suppression de fichiers, chacun se comporte à sa manière, ce qui donne des résultats de récupération différents et parfois même une récupération échouée.
Les informations données dans cet article aident à comprendre les principes généraux du fonctionnement du système d’exploitation Linux et les raisons des échecs fréquents de la récupération de fichiers supprimés avec des tailles et des noms exacts à partir des systèmes de fichiers Linux. Notre logiciel de récupération des données permet d’obtenir le meilleur résultat possible, même dans les cas les plus complexes. Veuillez vous référer aux produits logiciels pour plus d’informations.
Comment les données sont-elles organisées ?
Comme la plupart des autres systèmes de fichiers, les systèmes de fichiers Linux utilisent une organisation des données par blocs. Au niveau logique, les stockages de données sont exploités en petites unités de données – les secteurs – d’une taille normale de 512 octets. Vous pouvez imaginer les secteurs de stockage comme des cellules avec des nombres ordinaux. Pour écrire des fragments de données, il faut un ou plusieurs de ces secteurs. En lecture, le pilote de stockage adresse ce secteur pour les données.
Pour optimiser l’adressage du disque, le système de fichiers combine des ensembles égaux de secteurs en blocs adressables avec le pilote du système de fichiers au niveau logique. La taille minimale possible du bloc est d’un secteur. La plupart des systèmes de fichiers, y compris les systèmes de fichiers Linux, utilisent des blocs comme plus petite unité de disque adressable. Habituellement, un fichier ou son fragment de taille inférieure à un bloc prend le bloc entier. Certains systèmes de fichiers comme ReiserFS, cependant, peuvent utiliser l’espace restant à l’intérieur du bloc pour allouer de petits fichiers et fragments de fichiers.
Normalement, les données sur un stockage sont organisées de cette manière : un fichier est alloué dans un bloc ; si un fichier dépasse le bloc dans sa taille, le système de fichiers donne un bloc de plus pour allouer le fichier (sauf dans des cas comme avec ReiserFS). Les données sont écrites dans des blocs de disque libre, non utilisés par des fichiers ou des métadonnées (informations techniques du système de fichiers).
Espace libre et fragmentation
De nombreuses demandes séquentielles ou simultanées « créer un fichier », « ajouter des données », « tronquer des données », « supprimer un fichier » rendent l’espace libre sur le système de fichiers fragmenté.
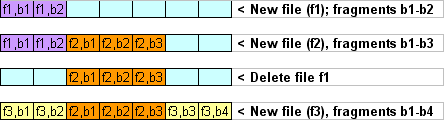
Image 1 : Fragmentation
La figure 1 montre l’exemple le plus simple de fragmentation. Au moment de l’écriture du fichier 3, il n’y avait pas de place pour écrire des fragments de fichier de manière séquentielle, de sorte que les fragments du même fichier ont été répartis en deux blocs libres non liés. En pratique, les gros fichiers peuvent se composer de centaines de fragments de données non liés, chacun de plusieurs blocs.
Le système de fichiers n’efface pas immédiatement les fragments du fichier sous la commande « supprimer » et marque plutôt la place occupée par ces fragments libres. Cette place est perçue par le nouveau fichier comme libre d’occupation. Pour cette raison, le fichier reste effectivement récupérable, à moins d’être écrasé par le nouveau.
Comment les fragments sont-ils liés ?
Le système de fichiers utilise des agents spéciaux décrivant les fichiers – les nœuds d’information (brièvement – inodes) – pour lier les informations sur les fragments de fichiers. Ces informations comprennent la description du type d’objet, de la taille, du tableau/liste/arbre de répartition.
En lisant un inode, le système de fichiers peut déterminer le type d’objet et décider des opérations ultérieures – lecture/écriture/manipulation. La taille de l’objet indique le nombre de blocs occupés par l’objet. Enfin, l’attribution des objets donne des informations sur l’emplacement réel des blocs de données.
Les données d’attribution d’objet sont organisées de la manière suivante : La partie principale de ces données est un tableau, une liste ou un arbre B de pointeurs vers des blocs de données ou vers des fragments continus de blocs. La première partie ou racine de ces informations est stockée comme une partie de l’inode.
Problème de restauration
Généralement, les systèmes de fichiers Linux nettoient une partie des informations de l’inode après la suppression des fichiers. Ils remplissent de zéros les informations relatives à la taille, au type/mode d’objet et à l’affectation de l’objet, ce qui entraîne la perte de toutes les informations relatives au fichier. Supposons que les fichiers 2 et 3 de la figure 1 sont des fichiers cryptés RAW sans en-tête, et que les deux ont pris des blocs complets, et ont été supprimés. En conséquence, aucune information sur l’allocation des fichiers n’est restée, rendant impossible pour le logiciel de récupération des données de détecter les limites des fichiers 2 et 3. Dans la pratique, les situations qui aggravent la récupération sont malheureusement trop courantes pour les systèmes de fichiers Linux. Cette situation est généralement influencée par des facteurs tels que la fragmentation des fichiers.
La solution
Heureusement, les logiciels de récupération des données offrent un ensemble de méthodes de récupération, mais sans garantie de résultat à 100 %. Elles comprennent :
- L’analyse d’un journal de système de fichiers. Les versions précédentes des descripteurs de fichiers peuvent toujours rester dans le journal.
- Analyse des structures incomplètes. Le logiciel peut prédire les fichiers du système de fichiers par des fragments non effacés de métadonnées de fichier qui peuvent encore se trouver sur le disque.
- Recherche basée sur la signature : Le logiciel recherche des fragments de fichiers connus et fait des suppositions quant au contenu des fragments suivants. Mais souvent, les résultats de la récupération ne donnent pas les tailles exactes des fichiers, sauf dans les cas où un en-tête de fichier contenant la taille du fichier en lui-même est trouvé. Cette méthode est impuissante dans les cas de fragmentation importante.
- Analyse statistique des fragments : Le logiciel fait l’hypothèse de liens entre les fragments en se basant sur des méthodes statistiques d’analyse des données. Cette méthode peut être utile pour les fichiers homogènes (la plupart des images bmp, certaines archives, etc.), mais elle est inutile pour les contenus hétérogènes (comme les images de CD/DVD, etc.).
- Recherche de structures de systèmes de fichiers perdus : Le logiciel trouve les structures perdues du système de fichiers, ce qui permet de déterminer la disposition des fragments perdus.
Si vous prévoyez de récupérer des données par vous-même, soyez prêt à faire beaucoup de travail manuel avec l’analyse de fichiers ou de fragments de fichiers sans nom, car la plupart des logiciels de récupération de données ne permettent souvent qu’une récupération incomplète après une restauration à partir de systèmes de fichiers Linux.
Les produits de récupération de données Hexascan sont développés avec des mécanismes puissants, notamment la recherche par signatures IntelliRAW™ permettant aux utilisateurs de reconnaître les types de fichiers et l’analyse des structures des systèmes de fichiers. Des techniques logicielles efficaces permettent d’obtenir le meilleur résultat de récupération avec un minimum d’efforts.



