
Chacun des articles donne une explication complète de l’organisation des données sur le stockage ainsi que les spécificités et les avantages de la technologie donnée, une compréhension qui peut vous aider à stocker correctement les données et à les récupérer en cas de perte, même à partir du stockage le plus complexe.
L’énorme quantité d’informations avec lesquelles les utilisateurs à domicile travaillent de nos jours a conduit à la nécessité de stocker des données volumineuses capables de contenir des quantités considérables de données. Des appareils à haute capacité de stockage sont devenus disponibles non seulement pour les grandes entreprises mais aussi pour l’usage domestique.
Les stockages RAID (Redundant Array of Independent Disks) sont parfaits pour le stockage de données à domicile mais, malheureusement, ne sont pas toujours fiables. Même les meilleurs systèmes RAID peuvent tomber en panne en raison de divers facteurs et entraîner la perte d’informations importantes pour l’utilisateur. Si cela vous arrive, nos produits de récupération des données vous aideront à récupérer les données perdues de votre système RAID, même dans les cas les plus graves.
Systèmes non redondants
Lorsque le terme RAID est appliqué au niveau 0 ou JBOD, celui-ci n’explique pas les fonctions réelles de ces technologies de stockage. Ces types de stockage fonctionnent de la manière suivante :
- JBOD : un stockage qui est étendu avec un certain nombre de disques, même de tailles différentes. Chaque composant de JBOD suit le précédent pour créer un stockage solide dont la taille est égale à la somme des tailles de chaque composant. JBOD est pris en charge par la plupart des puces RAID matérielles ainsi que par le RAID logiciel (par exemple, les disques dynamiques sous Windows peuvent s’étendre sur différents disques ou partitions de disques).
- RAID0 : Ensemble de bandes sur des disques de taille égale. Les données du RAID0 sont divisées en « bandes » de taille égale et sont réparties de manière cyclique sur tous les disques. La taille de ces « bandes » varie généralement de 512 octets à 256 Ko. La technique des bandes de données sert à répartir de longs fragments de données sur tous les disques. Cela permet d’envoyer des demandes d’échange de données à tous les disques simultanément et d’accélérer cette action grâce à la lecture ou l’écriture parallèle. Ces systèmes se caractérisent par une vitesse de fonctionnement maximale et une utilisation optimale de l’espace disque.
Les chances de récupération des données pour ces systèmes sont évidentes : même si un seul disque de ce RAID ne peut être lu, les données de ce composant deviennent irrécupérables. Si la défaillance d’un seul disque se produit sur JBOD, l’ensemble du fragment de plage devient irrécupérable. Pour le RAID0, cela pourrait affecter toutes les données sur le RAID (par exemple, si le RAID0 est construit sur 4 disques avec une taille de bande de 16KB, après la défaillance d’un seul disque, le RAID aura un « trou » de 16KB après chaque bloc de 48KB. En général, cela signifie que tout fichier d’une taille supérieure à 48KB ne peut pas être récupéré).
Note : Si un ou plusieurs disques de RAID0 ou JBOD ont échoué, arrêtez d’utiliser le disque et amenez-le à un laboratoire de récupération de données. Dans ce cas, seule une réparation physique du disque peut aider à récupérer les données.
Si la raison de la défaillance du RAID est autre que la défaillance d’un seul disque (par exemple, une réinitialisation des paramètres du contrôleur, la défaillance ou l’endommagement d’un contrôleur, etc.), les données restent récupérables même après l’endommagement logique d’un système de fichiers. La seule chose à faire dans ce cas est d’assembler le stockage solide d’origine à l’aide d’un logiciel de récupération des données. Pour cela, vous devez marquer les disques inclus dans le RAID, l’ordre initial des disques et la taille des bandes pour le RAID. Le logiciel de récupération des données lira les données des composants de la même manière qu’un contrôleur RAID et accédera aux fichiers complètement sur un RAID virtuellement reconstruit.
Miroirs
La technique du miroir est mise en œuvre dans RAID1. Les données de chaque composant du RAID sont dupliquées, ce qui permet de récupérer les informations perdues à partir de tout composant non endommagé du système RAID. Dans le RAID miroir, le contrôleur effectue des opérations de lecture en parallèle pour accélérer l’accès en lecture aux fichiers.
Ce type de stockage présente la redondance la plus élevée et les meilleures chances de récupération des données. La seule chose à faire est d’analyser une fois le stockage à l’aide d’un logiciel efficace de récupération des données.
Systèmes redondants avancés
Des systèmes redondants avancés sont créés pour faire un compromis entre la vitesse d’accès au stockage, la taille du stockage et la redondance. Ces systèmes sont généralement basés sur l’idée d’un striping du RAID0, mais les données de stockage sont étendues avec des informations supplémentaires – des informations de parité ajoutant de la redondance et permettant aux utilisateurs de récupérer des données ou même de continuer à travailler avec le stockage RAID après la défaillance de son composant.
Ces systèmes comprennent le RAID3, le RAID4 ou le RAID7 (un ensemble de bandes à parité dédiée), le RAID5 (un ensemble de bandes à parité distribuée) et le RAID6 (un ensemble de bandes à double parité distribuée). Le terme « simple » parité signifie que les données sont récupérables ou que le système est opérationnel après la défaillance d’un seul composant ; « double » parité – jusqu’à deux composants.
Le RAID3 et les systèmes similaires utilisent la technique classique du RAID0, complétée par un disque supplémentaire pour stocker la parité. Les systèmes RAID5 et RAID6 répartissent la parité entre tous les disques afin d’accélérer le processus de mise à jour de la parité pour les opérations d’écriture de données.
La récupération des données de ces systèmes est possible pour un RAID complètement intact si un (pour RAID3, RAID4, RAID5, RAID7) ou deux maximum (pour RAID6) composants restent illisibles.
Note : Si plus de disques tombent en panne que ce qui est autorisé, arrêtez immédiatement d’utiliser le stockage et emmenez-le à un laboratoire de récupération des données. La récupération des données n’est possible qu’avec l’aide d’un professionnel.
Si la récupération des données est possible sans réparation, vous devez assembler votre RAID à l’aide d’un logiciel de récupération des données spécifiant les disques (y compris les emplacements pour tout disque manquant), l’ordre des disques, la taille des bandes et un algorithme de distribution de parité. Le logiciel de récupération des données lira les données des composants du RAID de la même manière qu’un contrôleur RAID et accédera aux fichiers complètement sur un RAID virtuellement reconstruit.
Systèmes hybrides
Les configurations RAID-on-RAID sont souvent utilisées pour améliorer les performances globales, ajouter de la redondance et pour d’autres raisons liées aux performances. Généralement, ces systèmes sont des combinaisons des systèmes RAID mentionnés ci-dessus. Les plus courants sont des systèmes comme le RAID10 : plusieurs « miroirs » avec une « bande » par-dessus. Les miroirs assurent ici la redondance et une bande sur les miroirs augmente la vitesse de lecture/écriture. La récupération des données d’un tel système est assez simple : vous devez prendre tout composant non endommagé de chaque miroir et construire virtuellement le RAID0 par dessus.
Les systèmes plus avancés comprennent le RAID50 (une bande sur le RAID5), le RAID51 (un miroir du RAID5), etc. Pour reconstruire un tel système, il faut construire chaque composant du RAID (dans cet exemple, chaque RAID5) et construire le RAID0 pour le RAID50 sur l’ensemble du RAID5.
Nous recommandons le logiciel Hexascan Expert RAID comme étant le plus efficace pour la récupération de données et la reconstruction virtuelle de tout niveau de RAID.
Organisation des données
Les différents niveaux de RAID appliquent différentes techniques d’organisation des données pour différents objectifs. Chaque niveau de systèmes RAID a ses propres avantages et inconvénients.
Termes relatifs aux matrices RAID
Les informations techniques sur les matrices RAID sont généralement fournies dans des termes spéciaux décrivant ce type de stockage. Les termes les plus couramment utilisés pour désigner les stockages RAID complexes sont les suivants
- RAID – Redundant Array of Independent Disks (réseau redondant de disques indépendants). Ce terme désigne un système de stockage dans lequel des stockages indépendants sont combinés en un seul ensemble. En fonction de l’organisation réelle des données du stockage, ce schéma augmente sa stabilité, ses performances et sa fiabilité.
- RAID matériel – RAID piloté par le matériel. Le RAID matériel se compose d’une puce ou d’une carte de contrôleur RAID qui fait fonctionner la matrice et d’un ensemble de disques attachés. Le système d’exploitation détecte le stockage RAID complexe comme un seul périphérique de stockage solide. Les données sont gérées par un contrôleur matériel et peuvent être configurées avec les paramètres de son BIOS.
- RAID logiciel – RAID piloté par logiciel. Le RAID logiciel n’utilise aucun matériel et est créé par le système d’exploitation sur un ensemble d’unités de stockage indépendantes. Le système d’exploitation reconnaît le stockage RAID logiciel comme une unité de stockage solide. Les données sont exploitées par les pilotes du système d’exploitation en utilisant le temps CPU sans nécessiter de matériel supplémentaire (par exemple, RAID logiciel NT LDM, Linux, BSD, RAID macOS tels que LVM/LVM2 ou MD).
- RAID virtuel – RAID matériel ou logiciel qui est virtuellement reconstruit à partir de ses composants. Il s’agit d’un stockage virtuel créé par un logiciel de récupération de données pour simuler le stockage RAID original à des fins de récupération de données.
- Composant RAID (unité) – un disque ou une partition de disque utilisé(e) comme stockage de données pour le stockage RAID.
- Mirroring – une technique d’organisation des données basées sur la réplication des données sur des unités séparées. Un miroir créer une copie complète d’une unité et utilise une autre unité pour stocker cette copie. Cela garantit une tolérance élevée aux pannes : Si une unité tombe en panne, il reste une autre copie des données située sur une ou plusieurs autres unités de ce RAID. La technique de mise en miroir est mise en œuvre dans le RAID de niveau 1.
- Striping – une technique d’organisation des données basée sur la distribution de fragments de données entre les unités. Le striping de données permet aux utilisateurs d’augmenter de manière significative les performances d’entrée/sortie (E/S) d’un stockage RAID. Les données sur RAID sont divisées en petites parties (stripes) et réparties sur toutes les unités disponibles. Le striping accélère les performances de stockage grâce à la lecture/écriture parallèle sur toutes les unités indépendamment. Le striping est implémenté dans le RAID0.
- Parité – une technique d’organisation des données basée sur l’ajout d’un bit de données provenant de différentes unités RAID à une unité séparée. La parité permet d’augmenter la tolérance aux pannes d’un stockage : en cas de défaillance d’un lecteur, le contenu du lecteur défaillant peut être reconstruit sur un lecteur de remplacement en soumettant les données des autres disques à condition qu’un seul lecteur soit défaillant.
- Code Reed-Solomon – un algorithme de correction d’erreurs basé sur l’algèbre de Galois. Le code Reed-Solomon permet d’augmenter la fiabilité d’un stockage RAID. Cet algorithme est utilisé dans le RAID6.
Types de matrices RAID (niveaux)
Les niveaux de stockage RAID diffèrent selon les techniques d’organisation des données. La description détaillée des types de RAID les plus largement utilisés, avec des informations sur les avantages et les inconvénients de chaque niveau, est donnée plus loin.
RAID, niveau 0 (RAID0, data striping)
Le niveau 0 du RAID est le meilleur exemple de l’agrégation de données en tant que telle. Le terme RAID – Redundant Array of Independent Disks – n’explique pas vraiment la fonctionnalité de ce niveau RAID car il n’implique pas de redondance. Ce type de stockage peut être constitué de deux unités et plus. Les bandes sont définies comme des fragments de données où chaque bande de données est située sur une unité de stockage suivante.
![]()
La figure 1 montre les bandes de données utilisées dans le RAID0. Un tel schéma d’organisation des données permet d’accélérer les opérations d’E/S jusqu’à U fois (où U est le nombre d’unités dans le RAID0). Ceci est réalisé en envoyant des demandes d’E/S simultanées ou conséquentes à différentes unités (généralement des disques durs différents). Par exemple, pour lire les bandes 0..3 (un segment de données de la taille de 4 bandes), le contrôleur envoie 2 demandes de lecture simultanées : pour lire deux premières bandes de l’unité 1 et deux premières bandes de l’unité 2. Les unités effectuent la lecture physique simultanément et le contrôleur obtient le résultat deux fois plus rapidement.
Cette méthode d’organisation des données permet d’utiliser la quasi-totalité de l’espace de stockage des données sans redondance sur la zone des données. Cependant, la capacité de stockage du RAID 0 est parfois inférieure à la somme des tailles des unités individuelles car le contrôleur peut réserver un certain espace de stockage pour ses propres besoins techniques.
Avantages du RAID, niveau 0 :
- Performance extrêmement élevée dans les opérations de lecture et d’écriture.
- Mise en œuvre simple (même la plupart des contrôleurs SATA embarqués prennent en charge le RAID 0).
- Jusqu’à 100% d’espace disque pour les données.
- La solution RAID la plus rentable.
Inconvénients :
- Pas de tolérance aux fautes : La défaillance d’un seul appareil entraîne la perte de données.
- Perspectives de récupération.
- Panne de contrôleur/réseau démonté : Grâce aux informations sur la taille des bandes et l’ordre des unités, vous pouvez facilement récupérer les données perdues.
- Unité endommagée : Dès qu’une des unités est illisible, la récupération des données pour les segments de données suivants au-delà de la StripeSize* (UnitsCount-1) est impossible.
RAID, niveau 1 (RAID1, mise en miroir des données)
Le niveau 1 du RAID met en œuvre la technologie de mise en miroir des données. La mise en miroir crée la copie exacte des données et la stocke sur un lecteur spécial séparé. La capacité du RAID1 est égale à la taille de la plus petite unité de stockage sans l’espace qui peut être réservé par le contrôleur. Lorsque le contrôleur lit les données du RAID 1, il peut envoyer des requêtes à n’importe lequel des lecteurs pour accélérer le fonctionnement des entrées/sorties. L’opération d’écriture fonctionne soit en mode parallèle (sur les deux lecteurs simultanément), soit en conséquence (sur un lecteur après l’autre, ce qui peut être tolérant aux pannes). Le RAID1 ne permet pas la segmentation des données.
Avantages du niveau RAID 1 :
- Opérations de lecture rapide.
- Tolérance aux pannes accrue.
- Continue à fonctionner même lorsqu’il reste au moins un lecteur miroir (en « mode dégradé« ).
- Une des solutions les plus disponibles, supportée par la plupart des contrôleurs SATA embarqués.
Inconvénients :
- L’utilisation la plus inefficace de l’espace lecteur.
- Opération d’écriture lente.
- Perspectives de récupération
- Panne de contrôleur/réseau démonté : il est facile de récupérer toutes les données de n’importe quel appareil.
- Unité endommagée : les données peuvent être récupérées à partir de n’importe quelle unité lisible.
RAID, niveau 4 (RAID4, ensemble de bandes avec parité dédiée)
Le RAID 4 est la première tentative réussie de compromis entre la tolérance aux pannes, la vitesse et le coût. La technique mise en œuvre dans le RAID 4 est basée sur le Stripe Set habituel (comme dans le RAID0), complété par une unité spéciale supplémentaire pour stocker les informations de parité pour le contrôle des erreurs. Cette matrice peut être constituée de 3 disques ou plus. Ce schéma de stockage de données est également mis en œuvre dans le RAID de niveau 3 avec la différence de méthode de striping qui est au niveau octet pour le RAID3 et au niveau bloc (secteur) pour le RAID4.

Figure 4. Ensemble de bandes avec parité dédiée (RAID4).
La figure 4 montre la méthode de tolérance aux pannes en action. Le jeu de bandes stocke les données RAID réelles. Chaque « colonne » de bandes est additionnée avec XOR pour obtenir la parité.
Le RAID 4 présente des caractéristiques similaires à celles du RAID 0, comme des opérations de lecture rapide et une grande capacité de stockage,de plus, ce niveau de RAID intègre sa propre caractéristique de correction d’erreur interne étendue. Si une bande devient illisible, le contrôleur est capable de la reconstruire en se basant sur les informations des autres bandes et sur la parité. Le disque désigné pour la parité n’est pas utilisé pour le stockage des données, mais plutôt comme unité de sauvegarde.
Avantages du RAID, niveau 4 :
- Opérations de lecture toujours plus rapides.
- Haute tolérance aux pannes.
- Fonctionnement en « mode dégradé« , si l’un des lecteurs tombe en panne.
- Solution efficace en termes de tolérance aux pannes pour l’argent.
Inconvénients :
- Des opérations d’écriture remarquablement lentes : toute opération d’écriture/mise à jour nécessite la mise à jour des informations de parité sur un disque dédié ;
- Opérations de lecture lentes en mode dégradé en raison d’une charge élevée sur l’unité de parité.
- Perspectives de récupération.
- Panne de contrôleur/réseau démonté : récupération facile de toutes les données. Des disques N-1 sont nécessaires, les disques de données sont préférés (pour construire le RAID 0 virtuel) ; des informations sur l’ordre des disques et la taille des bandes sont nécessaires.
- Unité endommagée : les chances de récupération sont proches de 100 %, si un seul disque tombe en panne. Si deux ou plusieurs disques tombent en panne, le même problème que pour le RAID0 se produit.
RAID, niveau 5 (RAID5, ensemble de bandes à parité répartie)
Actuellement, le RAID5 est le meilleur compromis entre tolérance aux pannes, vitesse et coût. La technique utilisée dans le RAID5 est basée sur le Stripe Set habituel (comme dans le RAID 0) qui, à ce niveau, mélange les données et les informations de parité. Comme le RAID4, il nécessite au moins trois disques mais ne dispose pas de disque spécial pour stocker les informations de parité sans créer une telle « file d’attente » pour les mises à jour de parité lors des opérations d’écriture.
Selon l’objectif, la mise en œuvre, le détaillant et d’autres facteurs, le niveau 5 du RAID peut différer dans les méthodes de distribution de la parité sur l’ensemble des bandes. Les méthodes les plus courantes comprennent : Symétrique à gauche (distribution de parité dynamique vers l’arrière), Symétrique à droite (distribution de parité dynamique vers l’avant), Asymétrique à gauche (distribution de parité vers l’arrière) et Asymétrique à droite (distribution de parité vers l’avant).
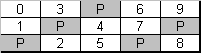
Figure 5. Distribution de parité symétrique à gauche (RAID5)
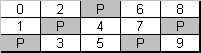
Figure 6. Distribution de parité asymétrique gauche (RAID5)
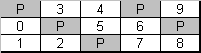
Figure 7. Distribution de parité symétrique droite (RAID5)
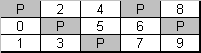
Figure 8. Distribution de parité asymétrique droite (RAID5)
La tolérance aux pannes est obtenue par les mêmes moyens que pour le RAID4 : le jeu de bandes stocke les données réelles et les informations de parité ; chaque colonne de bandes est additionnée dans une bande de parité de la colonne.
Le RAID5 combine les caractéristiques du RAID0 (opérations de lecture rapide et grande capacité) et du RAID4 (correction interne étendue des erreurs). Si la bande devient illisible, le contrôleur est capable de la reconstruire en se basant sur d’autres bandes et informations de parité. La capacité réelle de stockage du RAID5 est de (U-1) * (min(taille de l’unité) – Réservé).
Avantages du RAID, niveau 5 :
- Opérations de lecture toujours plus rapides.
- Écriture rapide en fonction des données et de la méthode de distribution de parité ;
- Tolérance aux pannes.
- Le RAID peut fonctionner en « mode dégradé« , si un disque tombe en panne.
- Solution efficace en termes de tolérance aux pannes pour l’argent.
Inconvénients :
- Des opérations d’écriture plus lentes par rapport au RAID 0.
- La vitesse des opérations d’écriture dépend du contenu et de la méthode de distribution de la parité.
Perspectives de récupération :
- Panneau de contrôle défectueux/désassemblé : il est facile de récupérer toutes les données. Tous les disques non endommagés sont préférés, mais N-1 est requis ; des informations sur l’ordre des lecteurs, la taille des bandes et la méthode de distribution de la parité sont nécessaires.
- Unité endommagée : les chances de récupération sont proches de 100 %, si un seul disque tombe en panne. Si deux ou plusieurs lecteurs tombent en panne, le même problème que pour le RAID0 se produit.
RAID, niveau 6 (RAID6, ensemble de bandes avec double parité répartie)
Le RAID6 est une solution de stockage de données à la fois fiable et économique. Il a été créé dans le but d’étendre le RAID5 avec une bande supplémentaire pour la redondance des données. À cette fin, l’algorithme du code de Reed-Solomon basé sur l’algèbre du champ de Galois est appliqué. Cette technique permet d’ajouter une unité supplémentaire pour la redondance des données et de corriger efficacement les erreurs de lecteur.
L’organisation des données sur le RAID 6 est similaire à celle du RAID 5 : les données et la parité (bande P) sont réparties sur les unités de stockage. La différence réside dans une bande supplémentaire (Q-stripe) située avec la P-stripe et contenant la somme des données GF.
Pour plus d’informations sur les algorithmes RAID6 et Q-stripe, veuillez consulter le site :
http://www.cs.utk.edu/~plank/plank/papers/CS-96-332
Avantages du RAID, niveau 6 :
- Opérations de lecture toujours plus rapides.
- Opérations d’écriture rapides selon la méthode de distribution des données et de la parité.
- Haute tolérance aux pannes.
- Le RAID peut fonctionner en « mode dégradé« , si un lecteur ou même deux disques tombent en panne.
- Solution efficace en termes de tolérance aux pannes pour l’argent.
Inconvénients :
- Des opérations d’écriture plus lentes par rapport au RAID0.
- La vitesse des opérations d’écriture dépend du contenu et de la méthode de distribution paritaire.
Perspectives de récupération :
- Panneau de contrôle défectueux/désassemblé : il est facile de récupérer toutes les données. Tous les lecteurs non endommagés sont préférés, mais N-1 ou N-2 est nécessaire ; des informations sur l’ordre des lecteurs, la taille des bandes et la méthode de distribution de la parité sont requises.
- Unité endommagée : les chances de récupération sont proches de 100 %, si seulement deux lecteurs tombent en panne. Si plus de deux lecteurs tombent en panne, le même problème qu’avec le RAID0 se produit.
RAID imbriqué : niveau 0+1, niveau 10, niveau 50, niveau 51 etc.
Des implémentations RAID imbriquées basées sur RAID0, niveau 5 et niveau 1 ont été créées pour améliorer les capacités de performance des systèmes RAID. Le niveau RAID 0+1 applique un miroir d’ensembles de bandes pour augmenter la tolérance aux pannes sans affecter les performances de stockage. Le niveau RAID 10 applique une extension des bandes pour refléter les données, ce qui améliore les performances et augmente l’utilisation de la capacité de stockage. Les niveaux RAID 0+1 et 10 nécessitent au moins quatre lecteurs. Le RAID50 est un ensemble de bandes de stockage RAID5 créé pour des raisons de performance et le RAID51 est un miroir du RAID5 créé pour la tolérance aux pannes (nécessitant au moins 6 disques).

Figure 2. Organisation des données sur un miroir de bandes (RAID0+1 ; 6 unités)
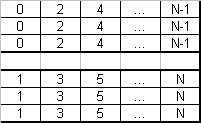
Figure 3. Organisation des données sur une bande de miroirs (RAID10 ; 6 unités, 2×3 miroirs)
Avantages des RAID imbriqués :
- Vitesse accrue ou tolérance aux pannes.
- Le RAID peut fonctionner en mode dégradé.
- RAID10 et RAID0+1 sont les solutions les plus abordables (certains contrôleurs embarqués prennent en charge ces types de RAID).
Inconvénients :
- Une solution coûteuse car la majeure partie de l’espace lecteur est utilisée pour les miroirs.
- Difficile à gérer et à maintenir.
Perspectives de récupération :
- Panne de contrôleur/réseau démonté : récupération facile de toutes les données.
- Unité endommagée : les chances de récupération sont proches de 100 % s’il est possible d’assembler virtuellement au moins un ensemble de bandes (RAID10, RAID50) ou au moins une instance miroir (RAID0+1, RAID51).
Récupération de données
Si l’on considère les chances de récupération des données décrites dans la section « Comprendre le RAID », si l’on utilise un logiciel efficace spécialisé dans la récupération et la reconstruction des systèmes RAID, les utilisateurs peuvent facilement récupérer eux-mêmes les données des stockages RAID. Les informations suivantes sont nécessaires pour lancer le balayage RAID :
- Niveau du RAID.
- Schéma de la disposition du RAID dans les unités.
- Paramètres du RAID : ordre des unités, taille des bandes, distribution de la parité (le cas échéant).
Après l’opération de récupération, vous pouvez enregistrer l’image de votre stockage RAID dans un endroit sûr et la charger dans un logiciel de récupération de données pour une analyse plus approfondie.
Nous recommandons Hexascan Expert RAID comme un utilitaire efficace spécialisé sur les systèmes RAID. Cette application prend en charge la reconstruction virtuelle et la récupération de données à partir de :
- RAID arrays levels 0, 1, 0+1, 10, 4, 5, 6, 50, 51, RAID 7 (variation matérielle du RAID4).
- RAID dégradés de niveau 1, 0+1, 10, 5 et 6.
- Systèmes de fichiers utilisés pour les stockages NAS et les serveurs avec des matrices RAID.
Articles connexes



